More on CJK Character Sets and Encoding Forms
[CJK]
[Home]
Contents
Definitions
- Character Set
- An abstract notion of a list of characters in a specified
order.
- Encoding
- The encoding of a character set
is how its characters are represented in bits and bytes.
A character set may be encoded in different
encoding forms.
- 7-bit Encoding
- Each character is encoded in one or more bytes depending on the
size of the character set.
Each byte is 8-bit long but the first bit is set to zero, so there are
only 7 variable bits. Some bytes, reserved for other purposes,
may not be used to encode printable characters. The best known
7-bit encoded character set is ASCII, in which every character is encoded in
exactly one byte. E-mail messages are usually sent in 7-bit
encoding because 8-bit or
16-bit encoded characters may not pass
correctly through some gateways.
- 8-bit Encoding
- Each character is encoded in one or more bytes depending on the
size of the character set.
All 8 bits are variable but some bytes, reserved for other purposes,
may not be used to encode printable characters. The vast
marjority of web pages is written in 8-bit encoding.
- 16-bit Encoding
- Each character is encoded in one or more pairs of
bytes. Some pairs of bytes may not be be used to encode printable
characters but any byte may occur within a pair.
UTF-16, the default
transformation format
of Unicode is a 16-bit
encoding form.
- Single-Byte Character Set
- Each character of a SBCS is encoded in exactly one byte.
7-bit encoded ASCII and the
8-bit encoded pre-Unicode
Western, Greek, Cyrillic etc. character sets are Single-Byte Character
Sets.
- Double-Byte Character Set
- A cover term for pre-Unicode CJK character sets. Each character of
a DBCS is encoded in exactly two bytes. A DBCS is always encoded
along with a 7-bit Single-Byte Character
Set such as ASCII or a
variant thereof, which results in a mixed system of double-byte and
single-byte encoded characters.
- 94x94 Character Set
- A DBCS whose characters are
arranged in a matrix of 94 rows and 94 columns and are identified
by their row-cell numbers (Japanese
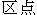 kuten,
Chinese
kuten,
Chinese  qu1wei4).
qu1wei4).